
Bạn đang xem: Append existing excel sheet with new dataframe using python pandas Tại Website vuongquocdongu.com
Please find below a helper function for appending a Pandas DataFrame to an existing Excel file.
If an Excel file doesn’t exist then it will be created.
UPDATE [2021-09-12]: fixed for Pandas 1.3.0+
The following functions have been tested with:
- Pandas 1.3.2
- OpenPyxl 3.0.7
from pathlib import Path
from sao chép import sao chép
from typing import Union, Optional
import numpy as np
import pandas as pd
import openpyxl
from openpyxl import load_workbook
from openpyxl.utils import get_column_letter
def copy_excel_cell_range(
src_ws: openpyxl.worksheet.worksheet.Worksheet,
min_row: int = None,
max_row: int = None,
min_col: int = None,
max_col: int = None,
tgt_ws: openpyxl.worksheet.worksheet.Worksheet = None,
tgt_min_row: int = 1,
tgt_min_col: int = 1,
with_style: bool = True
) -> openpyxl.worksheet.worksheet.Worksheet:
"""
copies all cells from the source worksheet [src_ws] starting from [min_row] row
and [min_col] column up to [max_row] row and [max_col] column
to target worksheet [tgt_ws] starting from [tgt_min_row] row
and [tgt_min_col] column.
@param src_ws: source worksheet
@param min_row: smallest row index in the source worksheet (1-based index)
@param max_row: largest row index in the source worksheet (1-based index)
@param min_col: smallest column index in the source worksheet (1-based index)
@param max_col: largest column index in the source worksheet (1-based index)
@param tgt_ws: target worksheet.
If None, then the sao chép will be done to the same (source) worksheet.
@param tgt_min_row: target row index (1-based index)
@param tgt_min_col: target column index (1-based index)
@param with_style: whether to sao chép cell style. Default: True
@return: target worksheet object
"""
if tgt_ws is None:
tgt_ws = src_ws
# https://stackoverflow.com/a/34838233/5741205
for row in src_ws.iter_rows(min_row=min_row, max_row=max_row,
min_col=min_col, max_col=max_col):
for cell in row:
tgt_cell = tgt_ws.cell(
row=cell.row + tgt_min_row - 1,
column=cell.col_idx + tgt_min_col - 1,
value=cell.value
)
if with_style and cell.has_style:
# tgt_cell._style = sao chép(cell._style)
tgt_cell.font = sao chép(cell.font)
tgt_cell.border = sao chép(cell.border)
tgt_cell.fill = sao chép(cell.fill)
tgt_cell.number_format = sao chép(cell.number_format)
tgt_cell.protection = sao chép(cell.protection)
tgt_cell.alignment = sao chép(cell.alignment)
return tgt_ws
def append_df_to_excel(
filename: Union[str, Path],
df: pd.DataFrame,
sheet_name: str = 'Sheet1',
startrow: Optional[int] = None,
max_col_width: int = 30,
autofilter: bool = False,
fmt_int: str = "#,##0",
fmt_float: str = "#,##0.00",
fmt_date: str = "yyyy-mm-dd",
fmt_datetime: str = "yyyy-mm-dd hh:mm",
truncate_sheet: bool = False,
storage_options: Optional[dict] = None,
**to_excel_kwargs
) -> None:
"""
Append a DataFrame [df] to existing Excel file [filename]
into [sheet_name] Sheet.
If [filename] doesn't exist, then this function will create it.
@param filename: File path or existing ExcelWriter
(Example: '/path/to/file.xlsx')
@param df: DataFrame to save to workbook
@param sheet_name: Name of sheet which will contain DataFrame.
(default: 'Sheet1')
@param startrow: upper left cell row to dump data frame.
Per default (startrow=None) calculate the last row
in the existing DF and write to the next row...
@param max_col_width: maximum column width in Excel. Default: 40
@param autofilter: boolean - whether add Excel autofilter or not. Default: False
@param fmt_int: Excel format for integer numbers
@param fmt_float: Excel format for float numbers
@param fmt_date: Excel format for dates
@param fmt_datetime: Excel format for datetime's
@param truncate_sheet: truncate (remove and recreate) [sheet_name]
before writing DataFrame to Excel file
@param storage_options: dict, optional
Extra options that make sense for a particular storage connection, e.g. hosting, port,
username, password, etc., if using a URL that will be parsed by fsspec, e.g.,
starting “s3://”, “gcs://”.
@param to_excel_kwargs: arguments which will be passed to `DataFrame.to_excel()`
[can be a dictionary]
@return: None
Usage examples:
>>> append_df_to_excel('/tmp/test.xlsx', df, autofilter=True,
freeze_panes=(1,0))
>>> append_df_to_excel('/tmp/test.xlsx', df, header=None, index=False)
>>> append_df_to_excel('/tmp/test.xlsx', df, sheet_name='Sheet2',
index=False)
>>> append_df_to_excel('/tmp/test.xlsx', df, sheet_name='Sheet2',
index=False, startrow=25)
>>> append_df_to_excel('/tmp/test.xlsx', df, index=False,
fmt_datetime="dd.mm.yyyy hh:mm")
(c) [MaxU](https://stackoverflow.com/users/5741205/maxu?tab=profile)
"""
def set_column_format(ws, column_letter, fmt):
for cell in ws[column_letter]:
cell.number_format = fmt
filename = Path(filename)
file_exists = filename.is_file()
# process parameters
# calculate first column number
# if the DF will be written using `index=True`, then `first_col = 2`, else `first_col = 1`
first_col = int(to_excel_kwargs.get("index", True)) + 1
# ignore [engine] parameter if it was passed
if 'engine' in to_excel_kwargs:
to_excel_kwargs.pop('engine')
# save content of existing sheets
if file_exists:
wb = load_workbook(filename)
sheet_names = wb.sheetnames
sheet_exists = sheet_name in sheet_names
sheets = {ws.title: ws for ws in wb.worksheets}
with pd.ExcelWriter(
filename.with_suffix(".xlsx"),
engine="openpyxl",
mode="a" if file_exists else "w",
if_sheet_exists="new" if file_exists else None,
date_format=fmt_date,
datetime_format=fmt_datetime,
storage_options=storage_options
) as writer:
if file_exists:
# try to open an existing workbook
writer.book = wb
# get the last row in the existing Excel sheet
# if it was not specified explicitly
if startrow is None and sheet_name in writer.book.sheetnames:
startrow = writer.book[sheet_name].max_row
# truncate sheet
if truncate_sheet and sheet_name in writer.book.sheetnames:
# index of [sheet_name] sheet
idx = writer.book.sheetnames.index(sheet_name)
# remove [sheet_name]
writer.book.remove(writer.book.worksheets[idx])
# create an empty sheet [sheet_name] using old index
writer.book.create_sheet(sheet_name, idx)
# sao chép existing sheets
writer.sheets = sheets
else:
# file doesn't exist, we are creating a new one
startrow = 0
# write out the DataFrame to an ExcelWriter
df.to_excel(writer, sheet_name=sheet_name, **to_excel_kwargs)
worksheet = writer.sheets[sheet_name]
if autofilter:
worksheet.auto_filter.ref = worksheet.dimensions
for xl_col_no, dtyp in enumerate(df.dtypes, first_col):
col_no = xl_col_no - first_col
width = max(df.iloc[:, col_no].astype(str).str.len().max(),
len(df.columns[col_no]) + 6)
width = min(max_col_width, width)
column_letter = get_column_letter(xl_col_no)
worksheet.column_dimensions[column_letter].width = width
if np.issubdtype(dtyp, np.integer):
set_column_format(worksheet, column_letter, fmt_int)
if np.issubdtype(dtyp, np.floating):
set_column_format(worksheet, column_letter, fmt_float)
if file_exists and sheet_exists:
# move (append) rows from new worksheet to the `sheet_name` worksheet
wb = load_workbook(filename)
# retrieve generated worksheet name
new_sheet_name = set(wb.sheetnames) - set(sheet_names)
if new_sheet_name:
new_sheet_name = list(new_sheet_name)[0]
# sao chép rows written by `df.to_excel(...)` to
copy_excel_cell_range(
src_ws=wb[new_sheet_name],
tgt_ws=wb[sheet_name],
tgt_min_row=startrow + 1,
with_style=True
)
# remove new (generated by Pandas) worksheet
del wb[new_sheet_name]
wb.save(filename)
wb.close()
Old version (tested with Pandas 1.2.3 and Openpyxl 3.0.5):
import os
from openpyxl import load_workbook
def append_df_to_excel(filename, df, sheet_name='Sheet1', startrow=None,
truncate_sheet=False,
**to_excel_kwargs):
"""
Append a DataFrame [df] to existing Excel file [filename]
into [sheet_name] Sheet.
If [filename] doesn't exist, then this function will create it.
@param filename: File path or existing ExcelWriter
(Example: '/path/to/file.xlsx')
@param df: DataFrame to save to workbook
@param sheet_name: Name of sheet which will contain DataFrame.
(default: 'Sheet1')
@param startrow: upper left cell row to dump data frame.
Per default (startrow=None) calculate the last row
in the existing DF and write to the next row...
@param truncate_sheet: truncate (remove and recreate) [sheet_name]
before writing DataFrame to Excel file
@param to_excel_kwargs: arguments which will be passed to `DataFrame.to_excel()`
[can be a dictionary]
@return: None
Usage examples:
>>> append_df_to_excel('d:/temp/test.xlsx', df)
>>> append_df_to_excel('d:/temp/test.xlsx', df, header=None, index=False)
>>> append_df_to_excel('d:/temp/test.xlsx', df, sheet_name='Sheet2',
index=False)
>>> append_df_to_excel('d:/temp/test.xlsx', df, sheet_name='Sheet2',
index=False, startrow=25)
(c) [MaxU](https://stackoverflow.com/users/5741205/maxu?tab=profile)
"""
# Excel file doesn't exist - saving and exiting
if not os.path.isfile(filename):
df.to_excel(
filename,
sheet_name=sheet_name,
startrow=startrow if startrow is not None else 0,
**to_excel_kwargs)
return
# ignore [engine] parameter if it was passed
if 'engine' in to_excel_kwargs:
to_excel_kwargs.pop('engine')
writer = pd.ExcelWriter(filename, engine='openpyxl', mode='a')
# try to open an existing workbook
writer.book = load_workbook(filename)
# get the last row in the existing Excel sheet
# if it was not specified explicitly
if startrow is None and sheet_name in writer.book.sheetnames:
startrow = writer.book[sheet_name].max_row
# truncate sheet
if truncate_sheet and sheet_name in writer.book.sheetnames:
# index of [sheet_name] sheet
idx = writer.book.sheetnames.index(sheet_name)
# remove [sheet_name]
writer.book.remove(writer.book.worksheets[idx])
# create an empty sheet [sheet_name] using old index
writer.book.create_sheet(sheet_name, idx)
# sao chép existing sheets
writer.sheets = {ws.title:ws for ws in writer.book.worksheets}
if startrow is None:
startrow = 0
# write out the new sheet
df.to_excel(writer, sheet_name, startrow=startrow, **to_excel_kwargs)
# save the workbook
writer.save()Usage examples:
filename = r'C:OCC.xlsx'
append_df_to_excel(filename, df)
append_df_to_excel(filename, df, header=None, index=False)
append_df_to_excel(filename, df, sheet_name='Sheet2', index=False)
append_df_to_excel(filename, df, sheet_name='Sheet2', index=False, startrow=25)
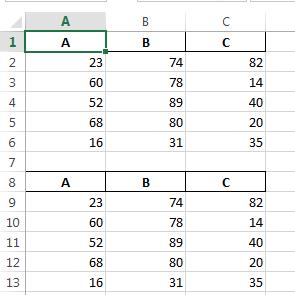
c:/temp/test.xlsx:

PS you may also want to specify header=None if you don’t want to duplicate column names…
UPDATE: you may also want to test this old solution
Xem thêm bài viết thuộc chuyên mục: Kĩ Năng Sống
Xem thêm bài viết thuộc chuyên mục: Tổng Hợp


![[100+] Mẫu CV tiếng Anh ấn tượng, phù hợp cho từng ngành nghề](https://vuongquocdongu.com/wp-content/uploads/2021/10/cv-tieng-anh-1-3-390x220.jpg)

